PFML:self-supervised learning of time-series data without representation collapse
ABSTRACT
论文大致介绍了下自监督学习主要是利用数据的内在结构进行学习,也就是通过模型自己给数据定义标签。但是自监督学习由于模型的复杂性会导致两个问题:
- 算法复杂,需要优化很多超参数;
- 表征坍缩(representation collapse),即模型输出一个持续的输入不变的特征表示。
关于这两个问题后面还会有详细的例子展示,本研究是为了处理表征坍缩的问题而提出了一种方法:PFML:Prediction of functional from masked latents。根据名字可知,有两个地方的亮点:
- 不在高维重构信号,而是预测嵌入(embedding)层;
- 对时间序列的统计值做预测。
INTRODUCTION
关于上面出现的算法复杂和表征坍缩这两个问题,有一些例子对应:
自监督学习基本有两大方法处理,一种是对比学习(contrastive learning),另一种是聚类思想(cluster),这两种方法都有局限性:
- 对于对比学习,正负样本的选择是很重要的。然而,并不总是那么明显哪些样本应该被归为正类和负类;
- 对于聚类思想,面对新的未见过的数据类型和任务会变得困难。
另一个非常常见的问题就是表征坍缩,很多论文在这方面也有方法处理:
对比学习中在Baevski等人(2020)的研究中,对目标表示有特殊的运用方式。这里的目标表示被以双重方式对待。作为正例时,它代表着与当前样本具有相似特征或者符合某种预期的样本关系;而作为负例时,它则是与当前样本有差异的样本的目标表示。通过这种方式,模型能够更好地学习到数据的特征表示,从而提高对数据的理解和处理能力,比如更精准地进行分类或者预测等操作。
Grill等人(2020)的研究中有两个关键操作:一是添加额外的预测变量到训练体系中。这就像给一个机器加入了新的零件,这个新预测变量能提供更多信息,让模型学习到更多模式,从而使模型的表现可能更好;二是采用所谓在线神经网络的移动平均来避免表征坍塌。在线神经网络在处理数据时是逐步更新的。移动平均是一种数据处理手段,它能平滑数据波动。表征坍塌会导致模型在学习过程中丢失了很多有用的特征表示。通过移动平均,可以让神经网络稳定下来,更好地保留不同的特征表示,避免过度拟合或者某些特征被忽略的情况,从而提高模型的泛化能力。
Bardes等人在2022年的研究中,对损失函数进行了改进,增加了一个正则化项。这个正则化项有两个主要作用。一是维持嵌入(embeddings)的方差,这有助于保持数据的多样性和特征的有效性。如果方差过度变化或缩小,可能导致模型学习到不准确或者过于局限的模式;二是去相关(decorrelate)每对变量,也就是减少变量之间的相关性。在很多情况下,高度相关的变量可能会给模型带来冗余信息,影响模型的泛化能力。通过去相关,可以让模型更聚焦于每个变量独立包含的信息,从而提高模型的性能和稳定性。
在data2vec(Baevski等人,2022)中,为解决表示坍缩问题,有两个关键做法:一是精心挑选模型超参数,合适的超参数有助于构建合理的模型结构与训练逻辑。二是通过特征归一化来促进目标表示的方差,从而解决了表征坍缩的问题。
METHOD
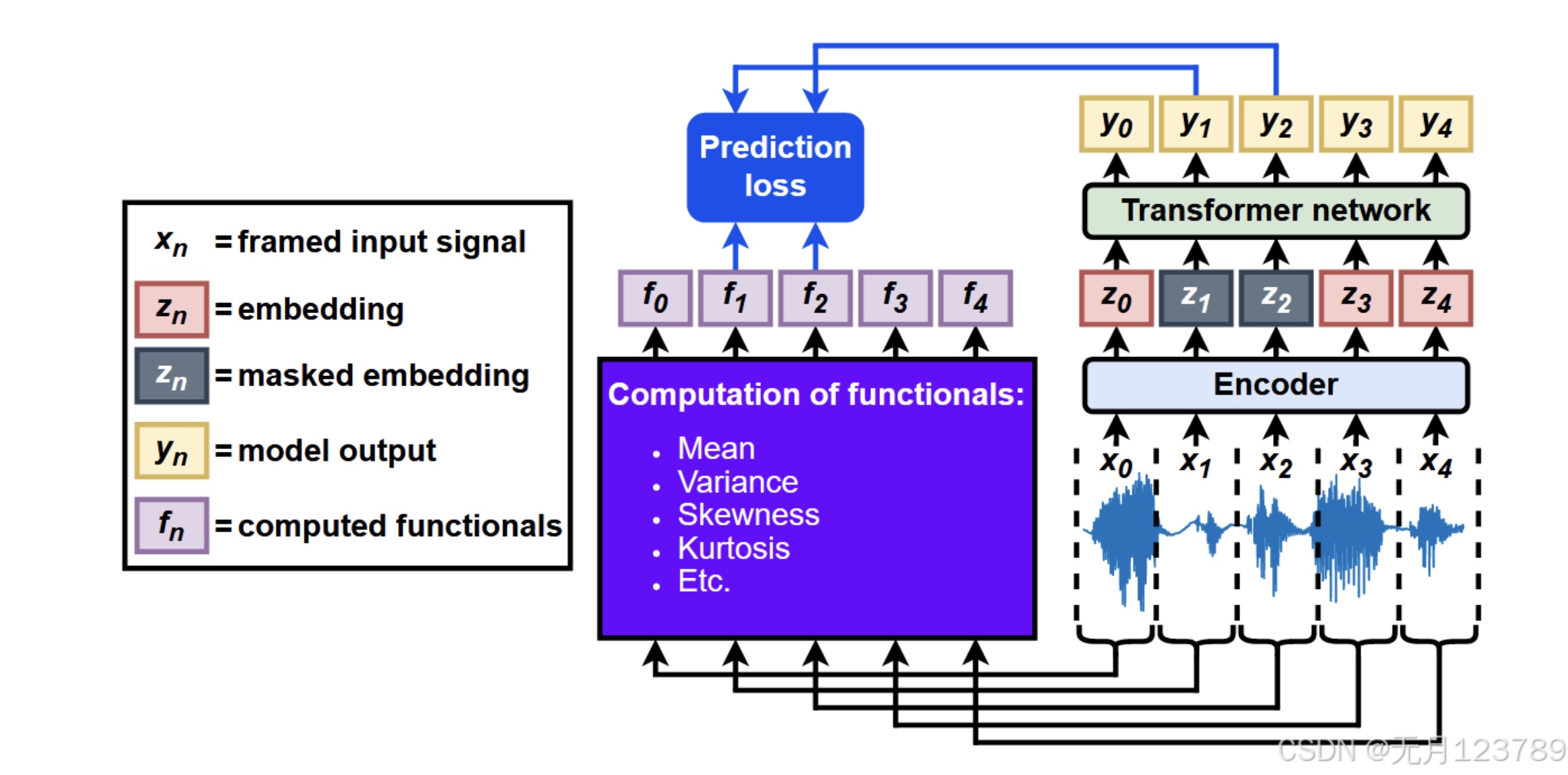
这张图是预训练主要的pipeline,原始信号先分帧成${[x_0, x_1, …]}, x_n = {[x_t, x_{t+1}, …, x_{t+N−1}]}$,然后输入给encoder,会输出$z_n$结果,也就是在嵌入层掩码后再给到Transformer,就会输出相应的结果。
另一部分是直接对原始信号计算11个泛函,分别是 mean(均值), variance(方差), skewness(偏度), kurtosis(峰度), minimum value(最小值), maximum value(最大值), zero-crossing rate (ZCR过零率), and the mean, variance, skewness, and kurtosis of the autocorrelation function (ACF自相关函数的均值等)。
关于prediction loss,就是计算Transformer输出和泛函输出结果之间的损失,采取的是MSE loss和L1 loss,个人认为对于不同的数据和任务类型可能会有不同的结果。在实验中也有所提及:对于IMU和EEG数据采用MSE loss;而语音情感部分数据集使用L1 loss
EXPERIENCES
实验采用的三种数据:
- infant posture and movement classification from multi-sensor IMU data
- emotion recognition from speech data
- sleep stage classification from EEG data
预训练部分,在Encoder和Transformer之间,它还加入基于CNN的相对位置编码和层归一化;当然Transformer输出后还加入了线性层以保证能和泛函部分做预测损失;
微调部分,共有两个阶段:
在第一阶段,在Transformer模型之后添加了两个随机初始化的全连接GeLU层,然后是softmax函数。然后,分别对这些层进行微调,将编码器和Transformer的权重冻结。
在第二阶段,使用与第一微调阶段相同的超参数对整个模型进行微调,但有一个例外:在20个训练周期的热身期间,学习率LR从0.001*LR线性增加到LR,然后根据验证损失的平台期,通过0.5的因子减少。
通过对每个样本的损失按其类别的倒数频率加权,使用加权分类交叉熵损失。还测试了预训练模型学习的特征的线性可分性。在这种情况下,在Transformer模型之后只添加一个线性层,并在编码器和Transformer的权重被冻结时微调这个单一层。
是否发生表征坍缩的方法:如果嵌入或模型输出的方差在连续10个预训练周期内低于0.01,并且在此期间验证损失一直在减少,就定义发生了表征坍缩。
RESULTS
Linear evaluation results for PFML, data2vec, MAE, and a randomly initialized model
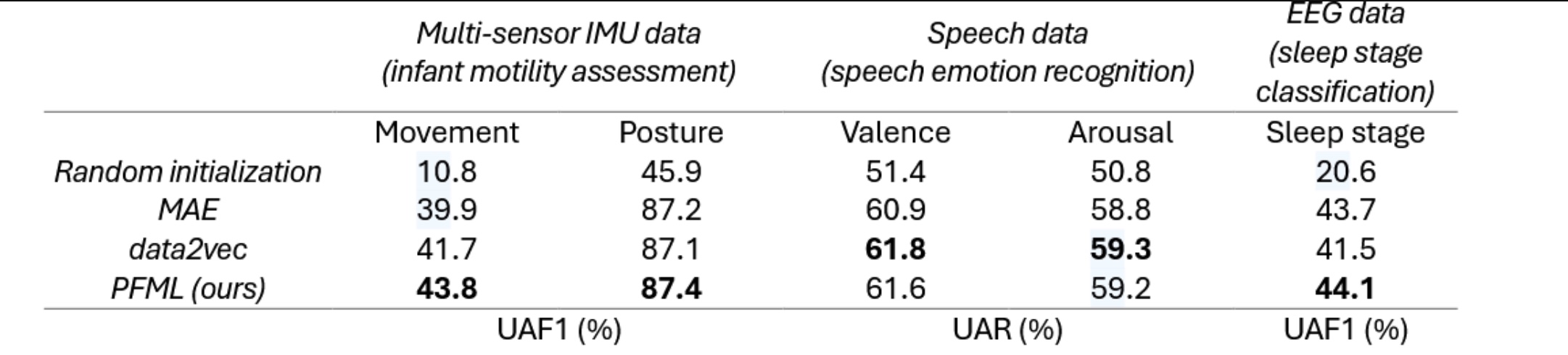
根据结果可以发现,PFML的表现要好于其他方法,除了语音情感识别领域data2vec的结果会更好一些
Frequency of representation collapse across 10 runs of PFML, data2vec, and MAE for each tested data modality
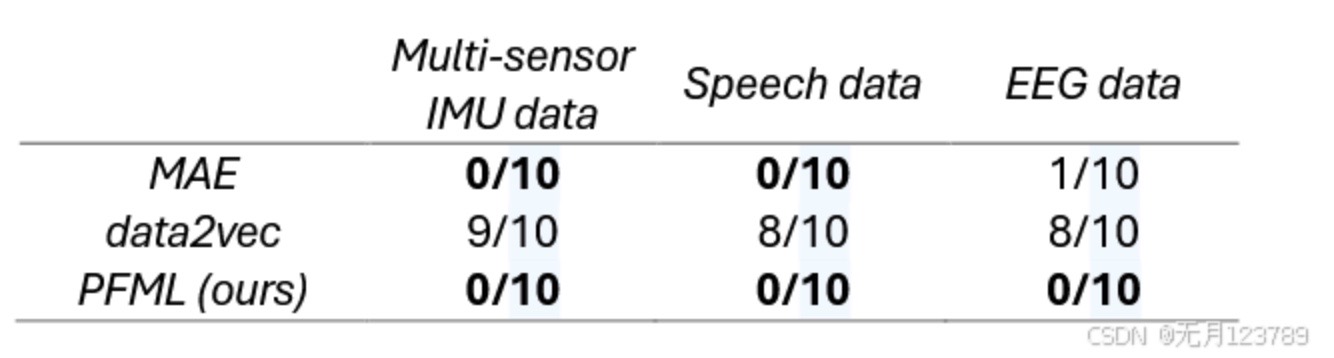
可以看到,PFML没有出现表征坍塌现象,而data2vec和MAE都有不同程度的表征坍塌现象。