DeepSeek LLM - Scaling Open-Source Language Models with Longtermism
paper:DeepSeek LLM
code:Github
前言
目前deepseek大火,很多文章也对其团队发出的技术报告进行了详细的解读和分析,但更需要的是从头开始一步一步展示deepseek发展过程,而这里就是他们的第一篇技术报告。
另外,现有的主流文章仅介绍了他们第一篇技术报告的大体框架。但正如标题所言,他们创新的亮点在于对缩放定律(Scaling Law)的详细研究,因此我的解读会着重介绍这一部分。
一、Introduction
1.大模型开发的流程遵从数据处理、模型搭建、模型训练验证、下游任务微调和模型评估这五步,后面会详细介绍deepseek团队如何处理这五步;
2.模型架构基本遵循LLaMA,如下图所示: 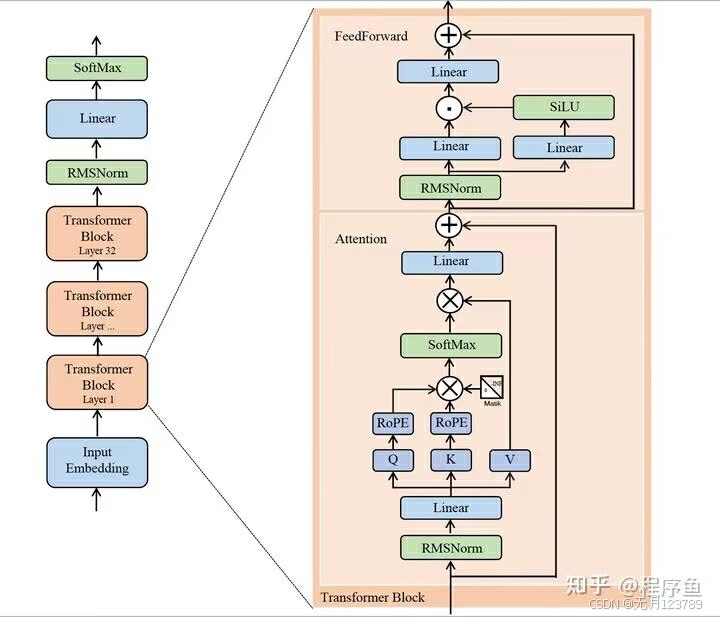
二、Pre-training
1.数据:处理数据包含三个基本阶段:deduplcation(去重)、filtering(过滤)和remixing(再混合)
(1)deduplcation:对语料库Common Crawl整体去重,可以提高去重比例;
(2)filtering:构建了结合语言和语义在内的详细评估手段;
(3)remixing:增加代表性不足领域数据集的占比,使不同数据集占比均衡,提升数据的全面性和多样性
另一部分是tokenization(分词),采用 BBPE算法。主要功能在于将句子构建为UTF-8编码的字节序列,提升了分词的细粒度。词汇量设置为102400进行分词器的训练
2.模型架构首先使用RMSNorm预归一化,RMSNorm根据均方根(RMS)对一层神经元的输入总和进行规范化,使模型具有重新缩放不变性和隐式学习率自适应能力;前馈网络使用激活函数SwiGLU,位置编码则是目前很流行的RoPE,通过旋转矩阵对绝对位置进行编码,同时在自注意力公式中纳入显式的相对位置依赖关系。最后,模型的主体依旧是Transformer。显然,deepseek第一代整体沿用当时最流行的LLaMA,同样也继承了其模型虽小但结果很优的效果。
deepseek初代模型包括7B和67B两种尺寸,67B尺寸的Transformer中的attention采用了Gruoped Query Attention代替MHA降低inference开销。GQA优点在于每组query共用同一组key和value。 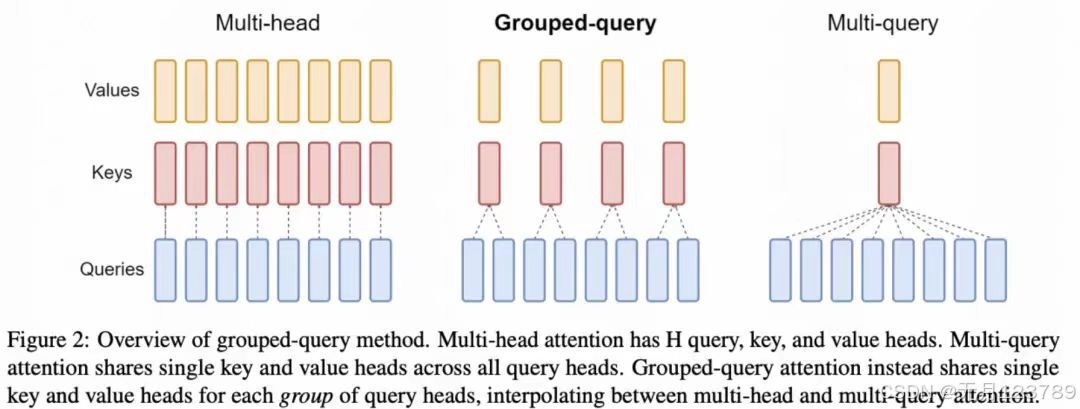 3.超参数:主要用多步学习率调度器代替了余弦学习率调度器。
3.超参数:主要用多步学习率调度器代替了余弦学习率调度器。
4.基本:
利用HAI-LLM训练和评估模型;
flash attention提升硬件利用率,减少显存访问,将大型矩阵分块为小块,计算局部注意力;注:这里有讲解很清晰的flash attention,可以根据需要详细阅读
ZERO-1数据并行的基础上划分优化器状态,即重叠(可以理解为最小化)计算和通信的等待开销;
层归一化,GEMM,Adam更新,它们都用于加速训练;并利用bf16精读训练,但fp32精读累积梯度
三、Scaling laws
基于先前研究,可以得出如下经验公式:$\mathbf{C=6ND}$,其中$\mathbf{C}$表示计算需要的预算,$\mathbf{N}$表示模型规模,$\mathbf{D}$表示数据规模
这里的研究会对批量大小(batch size)和学习率(learning rate)这两部分进行重新考量,为什么是这两个超参数呢?因为其余的超参数对模型的优化并不如这两个显著。
1.超参数的缩放定律:随着C的提升,批量大小和其产生正比关系,学习率则产生反比关系,这也与超参数的功能对应。
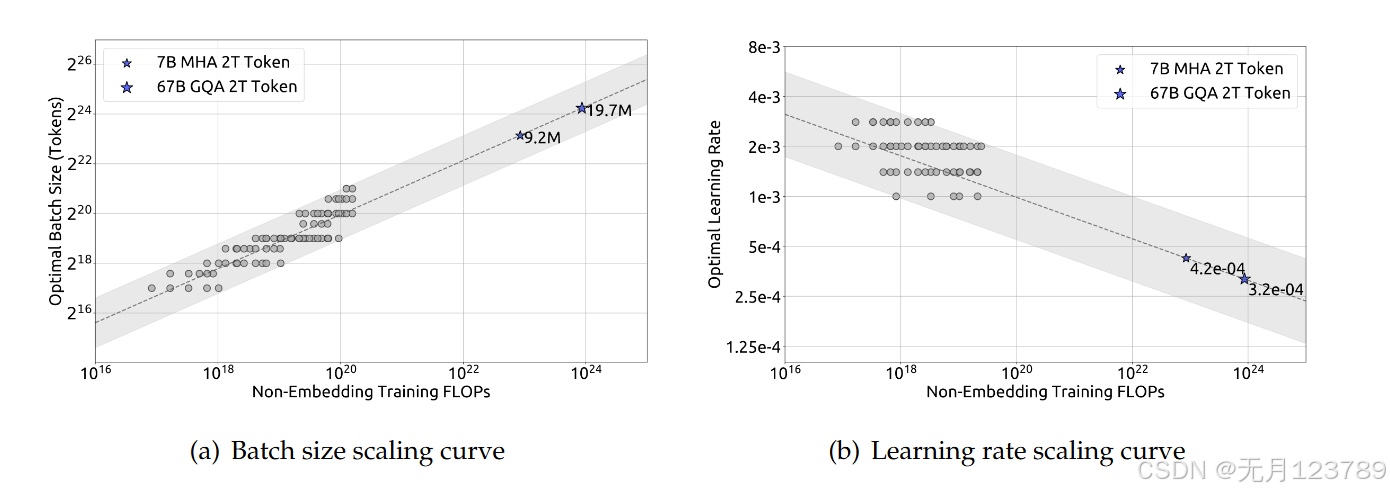 注:这里将泛化误差不超过0.25%的模型所使用的参数视为近最优超参数并进行采集
注:这里将泛化误差不超过0.25%的模型所使用的参数视为近最优超参数并进行采集
将上图中图线的关系拟合出来可以得到如下经验公式:
$\eta=0.3118·C ^{−0.1250}$ $B=0.2920·C ^{0.3271}$
但未考虑到计算预算之外的因素对超参数的影响,因此仍需要深入研究
2.估计最优模型与缩放指数的关系:目的在于寻找模型指数a和数据指数b,使其满足N正比于$C^a$,D正比于$C^b$
但这里存在问题,在先前公式$\mathbf{C=6ND}$中,$\mathbf{N}$的选取要么是非嵌入参数$\mathbf{N_1}$,要么是完整参数$\mathbf{N_2}$,前者并未考虑到注意力运算,后者又加入了词汇计算,尤其是在小模型中这些误差很显著。因此将$\mathbf{6N}$替换为$\mathbf{M}$表示,这里的$\mathbf{M}$包含了注意力运算但没有词汇运算,经验公式就表示为$\mathbf{C=MD}$
利用IsoFLOP拟合缩放曲线,得到结果如下所示: 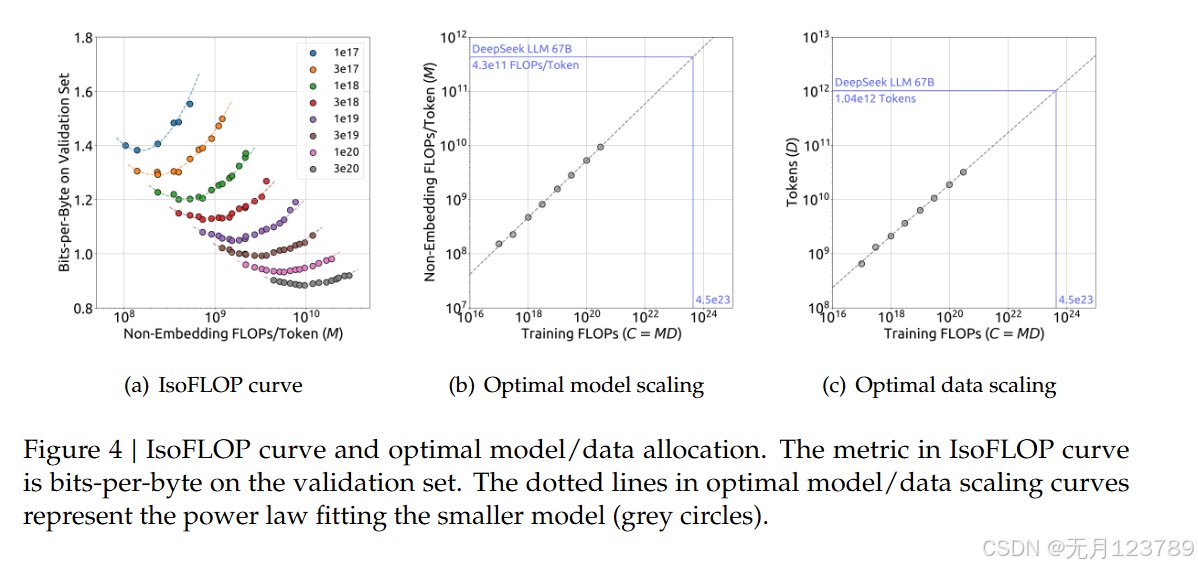 $M_{opt}=M_{base}·C^a, M_{base}=0.1715, a=0.5243$ $D_{opt}=D_{base}·C^b, D_{base}=5.8316, b=0.4757$
$M_{opt}=M_{base}·C^a, M_{base}=0.1715, a=0.5243$ $D_{opt}=D_{base}·C^b, D_{base}=5.8316, b=0.4757$
同样的拟合出的损失缩放曲线也可以很好的预测出7B和67B模型 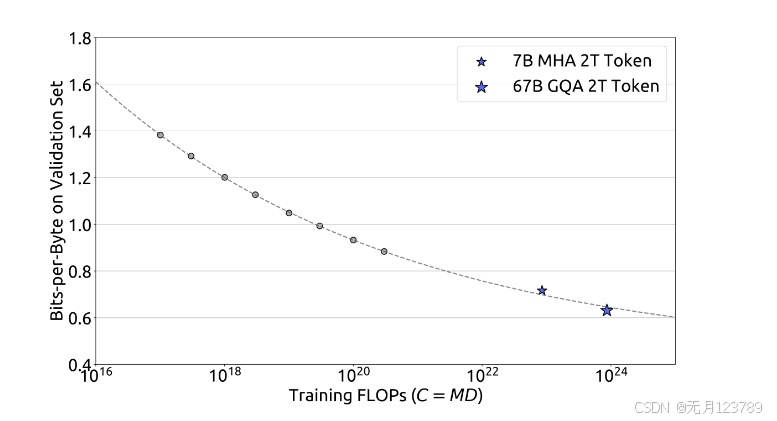
3.不同数据下的缩放定律:
随着数据质量的上升,模型扩展指数a上升,数据扩展指数b下降,也就是说增加的模型计算资源更多的应用到模型架构方面,这也提醒我们高质量的数据会让模型的预测难度更低且逻辑更加清晰,泛化性也更好
四、Alignment
1.SFT: Supervised Fine-Tuning:模型的微调对齐阶段一般采用监督微调,即利用已标注数据对模型进行微调,以提升模型的下游任务的性能。
其中GSM8K和HumanEval两个数据集持续改善7B模型,但对67B模型很快达到上限,为了减少不必要的聊天重复率,采用二阶段微调和DPO方法
2.DPO: Direct Preference Optimization:直接偏好优化方法是一种无监督的微调方法,它通过优化模型的偏好函数来学习到下游任务的偏好。这里主要围绕有用性和无害性构建DPO训练偏好数据
五、Evaluation
评估阶段直接看论文原文即可,有详实的结果展示~