浅谈autoencoder(1)——从autoencoder到VAE
前言
最近的研究刚好和自编码器有所联系,作为一个很大的神经网络框架,它的优势在于可以仅采集健康数据并训练出基于健康数据的模型,这样故障程度越大,离健康流形就越远,理论上可以有一个连续的状态监测框架。但他有一个致命的问题,就是它受工况的影响特别大,这个痛点问题在工业界非常常见。
最初的的研究仅针对同一工况进行分析,并将其集成到FPGA中。但随着工业界对不同工况的处理需求增加,解耦工况是成为一件越来越重要的事情。一般而言,工况包括环境参数(温度、电流等)和设备本身。我们需要尽可能消除环境带来的影响。只是实际上,工况和退化本身是强耦合的,是不可能完全消除的,只能通过训练尝试削弱工况的影响,这个点作为探索的问题本身,能延伸出许多思路(如强化学习、互信息解耦等),这次就从autoencoder出发。
autoencoder架构
autoencoder通常使用encoder-decoder标准架构,本质是对改变数据维度。从信息论的角度出发,增加维度可以将更多信息延展到不同方向,进而提高信息的表示能力;而减少维度是为了适配计算资源提高效率等。通常的流程是先将数据输入encoder,将其压缩到低维空间中,再用decoder还原。而被压缩到的低维空间就是latent space,如下图所示
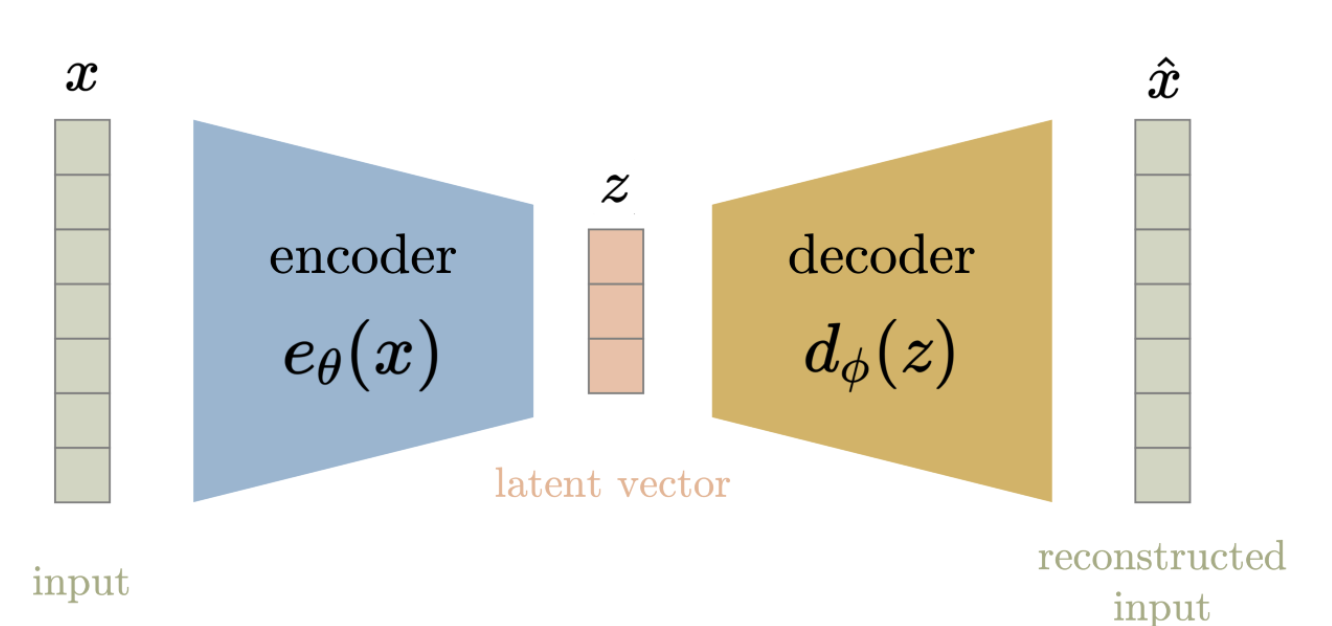
而encoder-decoder可以随意选择任何神经网络(CNN, LSTM, RNN等),损失通常为MSE,属于最标准的reconstruction loss。但如前文所述,它的问题在于工况对他的影响非常大,经常会错判健康和故障数据,这是因为经典的自编码器是确定性的复合映射:
\[x \xrightarrow{\text{Encoder } f} z \xrightarrow{\text{Decoder } g} \hat{x}\]目标是最小化重建误差(如 MSE): \(\mathcal{L}_{\text{AE}} = \|x - g(f(x))\|^2\)
这种天然的“确定性”在现实世界中是几乎不可见的。现实世界中的数据多为概率分布,这也是它难以解耦工况并实现退化状态预测的原因。
VAE原理介绍
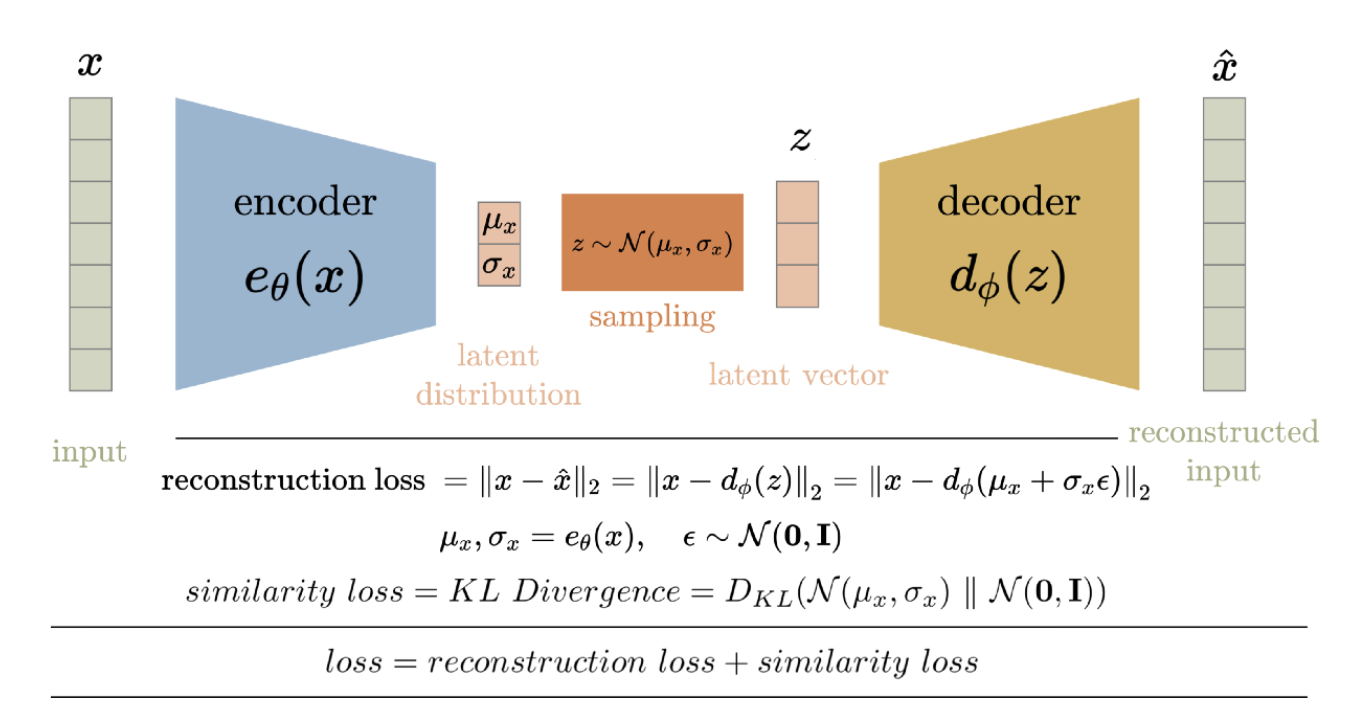
既然现实生活中更多的是概率分布,因此引入概率是很关键的事。而VAE就对autoencoder做了两处概率化改造:
- encoder输出分布参数而非直接输出latent space \(q_\phi(z|x) = \mathcal{N}\!\left(z;\, \mu_\phi(x),\, \text{diag}(\sigma_\phi^2(x))\right)\)
- 重参数化,将采样移除梯度空间 \(z = \mu_\phi(x) + \sigma_\phi(x) \odot \varepsilon, \qquad \varepsilon \sim \mathcal{N}(0,I)\)
这里的创新点就是将latent space转换为概率分布,从而引入了概率的表示能力。而VAE的损失函数则为ELBO,即证据下界(Evidence Lower Bound),它用于优化模型参数,使模型的重建误差最小化:
\[\log p_\theta(x) \;\geq\; \underbrace{\mathbb{E}_{q_\phi(z|x)}\!\left[\log p_\theta(x|z)\right]}_{\text{重建项}} \;-\; \underbrace{D_{\text{KL}}\!\big(q_\phi(z|x)\,\|\,p(z)\big)}_{\text{KL 正则项}} \;=: \mathcal{L}_{\text{ELBO}}\]目前这些式子乍一看很复杂,我们一点一点拆解。
损失函数生成
首先,latent space从一个确定的向量$z$变成了概率分布$q_\phi(z|x)$,从而引入了概率的表示能力,显然取的是高斯分布,且它的作用不仅仅是为了概率化latent space,更是因为真实的后验分布$p_\theta(z|x)=\frac{p_\theta(x|z)p(z)}{p_\theta(x)}$无法直接计算(分母是很复杂的积分运算),所以需要用$q_\phi(z|x)$来近似$p_\theta(z|x)$。
进而,损失就是衡量$q_\phi(z \vert x)$和$p_\theta(z \vert x)$之间的差距。我们从KL散度出发来推导ELBO:
\[D_{\text{KL}}\!\big(q_\phi(z|x)\,\|\,p_\theta(z|x)\big) = \mathbb{E}_{z\sim q_\phi(z|x)}\!\left[\log q_\phi(z|x) - \log p_\theta(z|x)\right]\]用贝叶斯公式展开真实后验:
\[p_\theta(z|x) = \frac{p_\theta(x|z)\,p(z)}{p_\theta(x)}\]代入:
\[\begin{aligned} D_{\text{KL}} &= \mathbb{E}_q\!\left[\log q_\phi(z|x) - \log p_\theta(x|z) - \log p(z) + \log p_\theta(x)\right] \\ &= \mathbb{E}_q\!\left[\log q_\phi(z|x) - \log p(z)\right] - \mathbb{E}_q\!\left[\log p_\theta(x|z)\right] + \log p_\theta(x) \end{aligned}\]注意最后一项 $\log p_\theta(x)$ 不依赖于 $z$,所以期望可以去掉。
整理一下,把 $\log p_\theta(x)$ 单独放左边:
\[\log p_\theta(x) = \underbrace{\mathbb{E}_{q_\phi(z|x)}\!\left[\log p_\theta(x|z)\right] - D_{\text{KL}}\!\big(q_\phi(z|x)\,\|\,p(z)\big)}_{\text{这就是 ELBO,记作 } \mathcal{L}(\theta,\phi;x)} + \underbrace{D_{\text{KL}}\!\big(q_\phi(z|x)\,\|\,p_\theta(z|x)\big)}_{\geq\, 0}\]因为 KL 散度永远非负,所以:
\[\boxed{\log p_\theta(x) \;\geq\; \mathbb{E}_{q_\phi(z|x)}\!\left[\log p_\theta(x|z)\right] - D_{\text{KL}}\!\big(q_\phi(z|x)\,\|\,p(z)\big) =: \mathcal{L}(\theta,\phi;x)}\]这就是证据下界(Evidence Lower BOund,ELBO)。最大化 ELBO 就能间接最大化边缘似然 $\log p_\theta(x)$。经过观察可以发现,当decoder同样为高斯分布时,减号前一项就是重建项;而KL项正是为了让latent space保持标准高斯分布的形状。
而代码中的损失是梯度下降的,因此我们取负,最小化损失也就是最大化 ELBO:
1
2
3
4
5
6
7
8
9
10
11
12
# 重建项(通常取负对数似然,即 MSE 或 BCE)
reconstruction = F.mse_loss(x_recon, x, reduction='sum') # ≈ -E[log p(x|z)]
# KL 项(散度,非负)
kl_divergence = 0.5 * torch.sum(mu**2 + logvar.exp() - logvar - 1)
# 总损失 = 重建 + KL = -ELBO
loss = reconstruction + kl_divergence
# 梯度下降最小化 loss
loss.backward()
optimizer.step()
采样和可导
由于我们将latent space变成了概率分布,需要采样z才能继续decoder解码。但采样操作对参数$\phi$是不可导的,这就无法进行梯度下降操作。
为了解决这个问题,随机性就被外包给一个标准高斯噪声$\varepsilon$: \(z = \mu_\phi(x) + \sigma_\phi(x) \odot \varepsilon, \qquad \varepsilon \sim \mathcal{N}(0,I)\)
这样,梯度就可以顺利反向传播: \(\nabla_\phi \mathcal{L} = \nabla_\phi \mathbb{E}_{\varepsilon}\!\left[\log p_\theta(x|\mu_\phi(x)+\sigma_\phi(x)\odot\varepsilon)\right] - \nabla_\phi D_{\text{KL}}\)
这就是重参数化技巧,为了保证神经网络可以正常训练。
局限性
尽管VAE将latent space转换为概率分布的形式,但总体来看它还是采样了z,再进行常规autoencoder操作,而损失仅仅是重建损失和KL正则化的结合。在实际处理变工况的退化问题时,latent space并不会提供太大的帮助,毕竟它仅是个特征的低维编码,VAE的优势在于可以在latent space中采样,进而体现出autoencoder不存在的生成能力,但这件事并不适配我们案例的需求,必须从方法层面进行改变。